TL;DR: AI search platforms like ChatGPT, Google Gemini, and Perplexity AI are fundamentally changing how patients discover cosmetic surgeons in America, making visibility inside AI-generated answers potentially more valuable than traditional first-page Google rankings.
For over a decade, finding a cosmetic surgeon followed a predictable pattern. Patients searched Google, clicked the top three results, compared websites, and booked consultations. That linear journey is ending. According to StatCounter, while Google still commands over 89% of search market share, the way people use search is changing rapidly. AI platforms now deliver curated answers, structured summaries, and provider recommendations without requiring users to click through to traditional websites.
The Answer Engine Revolution
OpenAI reported that ChatGPT reached over 100 million weekly active users within its first year, signaling massive adoption of conversational AI for research. Perplexity AI has also reported tens of millions of monthly queries with strong year-over-year growth. When patients now ask AI platforms about rhinoplasty surgeons in Dallas or facelift specialists in Miami, they receive synthesized answers pulling from multiple authoritative sources, often without ever visiting a clinic website.
Deloitte’s Digital Consumer Trends research highlights increased trust in AI-assisted information discovery when answers appear structured and properly cited. This shift creates a fundamental challenge for cosmetic surgery practices. If your clinic isn’t part of the AI synthesis, you effectively disappear from the conversation before patients even know you exist.
Why Traditional SEO Metrics Are Changing
Traditional search engine optimization focused intensely on securing the number one ranking position. AI search disrupts this model in three critical ways. First, when Google AI Overviews provide detailed answers, BrightEdge and Search Engine Land studies show many users never scroll further or click through to websites.
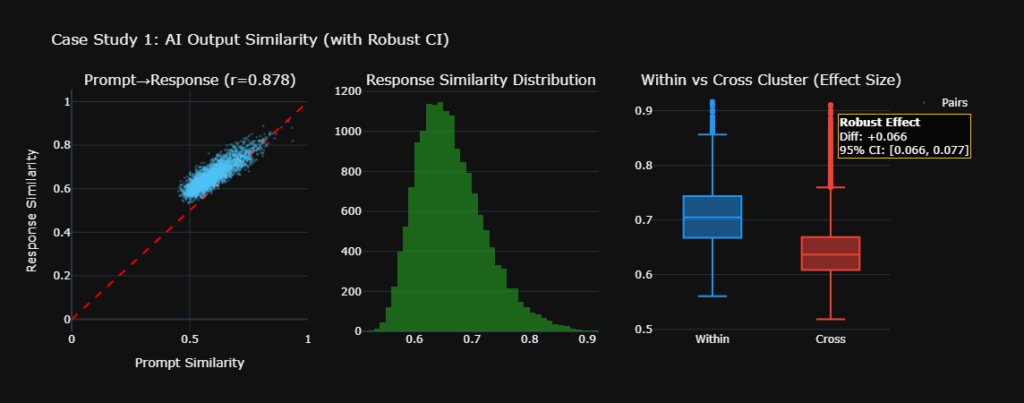
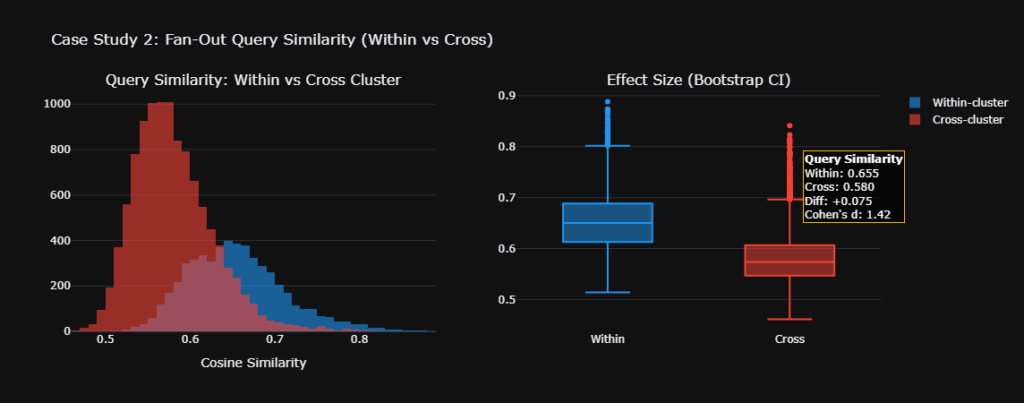
Second, AI platforms blend information from multiple authoritative domains simultaneously. A clinic ranking third or fourth might still appear prominently in an AI summary if its content demonstrates genuine authority and clarity. This shifts competition from pure ranking position to semantic relevance and credibility signals that machines can interpret.
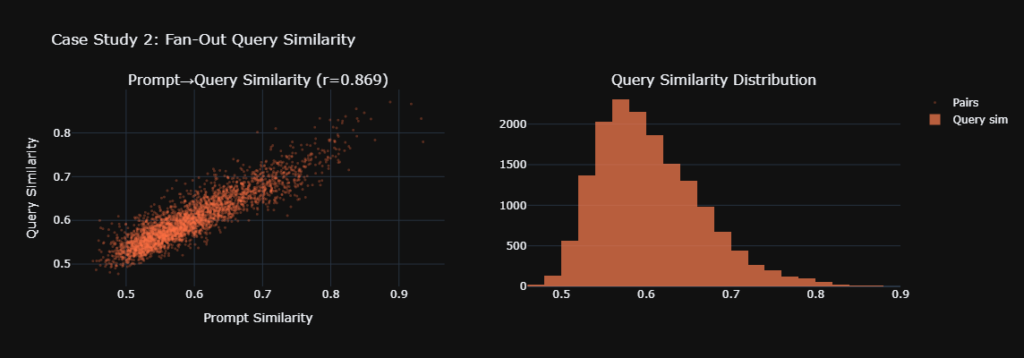
Third, conversational queries expand naturally. A patient might start by asking about the best breast augmentation surgeon in Chicago, then immediately follow up with questions about recovery time, implant types, and complication rates. Clinics with comprehensive educational content surface across multiple conversational layers, creating sustained visibility throughout the research journey.
Authority Signals That Drive AI Visibility
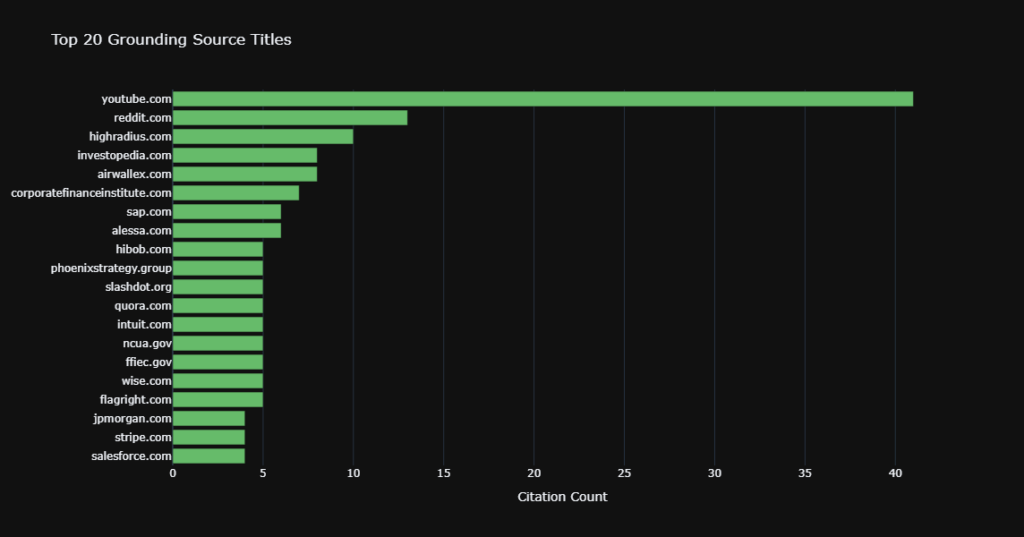
AI models prioritize patterns of authority when synthesizing answers. Research from McKinsey shows patients increasingly rely on digital tools to compare providers before scheduling consultations, while Accenture reports nearly half of patients use multiple online sources before making healthcare decisions. To appear in AI-generated answers, clinics need consistent citations across reputable medical directories, professional associations like the American Board of Plastic Surgery, and educational platforms.
Structured educational content matters enormously. Detailed procedure guides covering candidacy requirements, risks, recovery timelines, and realistic outcomes improve semantic clarity that AI systems can extract and reference. Short promotional pages rarely make it into AI synthesis because they lack the depth and educational value these systems prioritize.
Practical Steps for Cosmetic Surgery Practices
- Create 1,000 to 2,000-word educational guides for each major procedure, citing peer-reviewed medical sources and professional associations
- Implement structured data markup for physician credentials, reviews, FAQs, and medical procedures to support AI extraction
- Build surgeon-led thought leadership through articles and commentary on authoritative healthcare platforms
- Regularly test how AI platforms answer location-specific queries about your specialties and procedures
- Maintain consistent review profiles on platforms like Healthgrades and RealSelf to strengthen authority signals
Many cosmetic surgery websites still prioritize visual design over structured information architecture. While aesthetics matter for patient experience, AI search prioritizes clarity, depth, and factual consistency. Clinics without comprehensive FAQ sections, detailed procedure pages, and consistent credential listings risk what analysts call the “non-existent clinic” effect, where AI systems simply don’t recognize their authority footprint.
This creates compounding disadvantages in competitive metros like Los Angeles, New York, or Houston. Early adopters who invest in structured educational ecosystems build digital trust that accumulates over time as AI systems train on available data. Those who delay may find competitors permanently embedded in AI summaries for key procedure queries in their markets.
Key Takeaways
- AI search platforms like ChatGPT, Google Gemini, and Perplexity AI are replacing traditional search behavior for cosmetic surgery research, with many patients never clicking through to clinic websites
- Appearing inside AI-generated answers may soon drive more consultation inquiries than achieving traditional first-page Google rankings alone
- Authority signals that influence AI visibility include consistent citations across medical directories, structured educational content, clear credential presentation, and third-party validation through review platforms
- Cosmetic surgery practices should create comprehensive 1,000+ word procedure guides, implement structured data markup, and regularly test their visibility in AI platform responses to location-specific queries
- Early adopters gain compounding advantages as AI systems continuously train on authoritative content, making immediate action critical for maintaining competitive visibility in local markets