TL;DR
We generated 180 finance-domain prompts across 3 topic clusters. We ran them through Google Gemini with live Google Search grounding. Then we measured how similar the AI’s responses and search queries were.
The results were striking:
- Similar prompts produce near-identical responses. r = 0.878. Bootstrap confidence interval confirms significance.
- Similar prompts trigger similar grounding searches. r = 0.869. Mantel permutation test p is less than 0.001.
- The implication: Companies can reduce AEO monitoring costs by approximately 85% by tracking seed prompts instead of every variation.
The Problem: AEO Is Expensive
Answer Engine Optimization is becoming critical for B2B companies. But it has a scaling problem.
Unlike traditional SEO, where you optimize pages and track rankings for a defined keyword set, AEO requires monitoring how AI systems respond to natural-language prompts. And those prompts are infinite.
“What is the best cash flow software for B2B SaaS?”
“Top cash flow tools for mid-market companies”
“How does cash flow forecasting work for fintech lenders?”
“Cash flow management platforms with NetSuite integration”
Each could trigger different AI responses, different grounding searches, and different brand mentions. Track them all individually and costs scale linearly. For a company monitoring 500 plus prompts across multiple AI platforms, this becomes unsustainable.
The question we set out to answer: Can you track one prompt and confidently infer what the AI would say for dozens of similar prompts?
Research Design
Two hypotheses:
- AI Output Similarity. Do semantically similar prompts produce semantically similar AI responses?
- Fan-Out Query Similarity. Do similar prompts trigger similar grounding searches?
If both are true, companies can consolidate prompts into clusters and monitor only representative seed prompts. Dramatically reducing cost and workload.
Methodology
We designed a controlled experiment with three distinct topic clusters in B2B finance:
Cash Flow. Base queries on free cash flow and cash flow forecasting. Example: “free cash flow explained for B2B SaaS”
Payment Processing. Base queries on B2B payment automation and cross-border payments. Example: “best cross-border payments tools with Stripe”
Fraud Detection. Base queries on transaction fraud detection and AML compliance. Example: “how AML compliance works for a compliance officer”
Each cluster contained 60 prompts. 180 total. Generated from 60 templates that varied across 7 context dimensions drawn from real B2B finance scenarios:
- Personas: CFO, FP&A lead, treasury manager, AR manager, controller
- Industries: B2B SaaS, fintech lender, payments platform, credit unions
- Geographies: Ireland, US, UK
- Integrations: NetSuite, Xero, SAP, Stripe, QuickBooks, Sage, HubSpot
- Company sizes: SMB, mid-market
- Time periods: daily, weekly, monthly, quarterly
- Metrics: runway, DSO, DPO, burn rate, working capital, net revenue retention
Prompts ranged from 6 to 20 words. Mixed styles including questions, commands, fragments, and phrases to simulate realistic user behavior.
Measurement
All 180 prompts went to Google Gemini 3.0 Flash with grounding enabled. For each prompt we captured:
- The AI’s full text response
- The grounding search queries the AI generated
- The grounding source URLs and titles
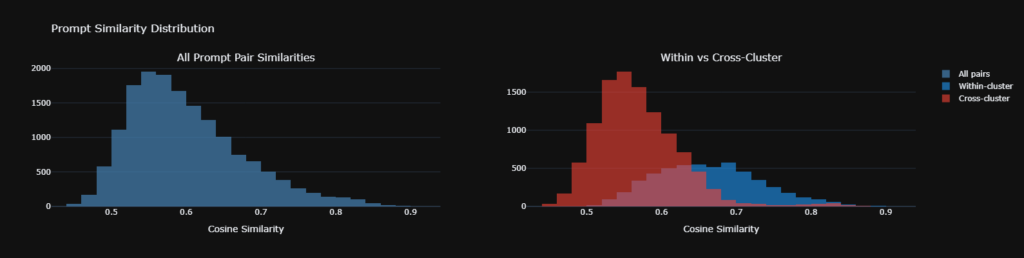
We computed semantic similarity using Gemini Embedding-001. Not TF-IDF. This captures meaning, not just word overlap. TF-IDF would score “money” and “capital” as zero percent similar. Embeddings correctly identify them as semantically close.
All similarity scores used cosine similarity on L2-normalized embedding vectors.
Results
Case Study 1: AI Output Similarity
Do similar prompts produce similar responses?
Yes. With extremely strong evidence.
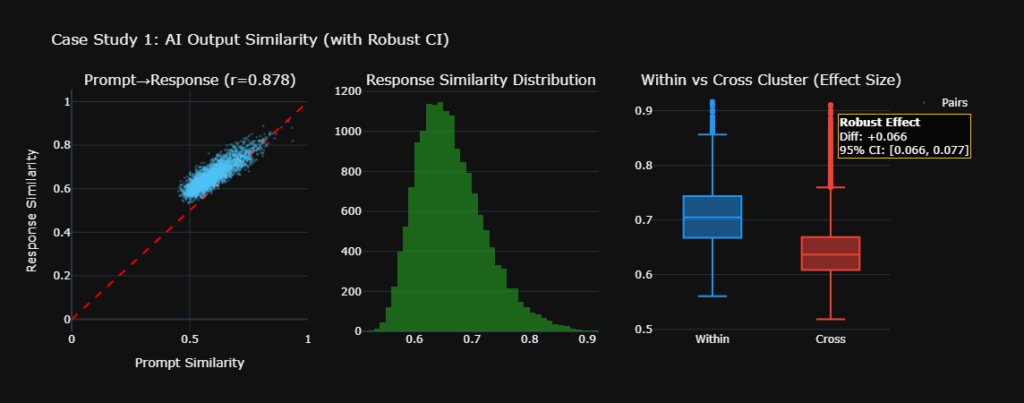
The Pearson correlation between prompt similarity and response similarity was r = 0.878. This means 77% of the variance in response similarity is explained by prompt similarity alone.
To put this in context:
- r = 0.3 would be interesting but weak
- r = 0.5 would be moderate, worth investigating
- r = 0.878 is near-perfect linear relationship
Control Group Validation
We verified our measurement using within-cluster versus cross-cluster comparisons:
- Within-cluster response similarity, same topic: 0.664
- Cross-cluster response similarity, different topics: 0.569
- Cohen’s d: 1.27, classified as very large effect
The AI clearly distinguished between topics. Cash flow prompts produced cash flow answers. Fraud prompts produced fraud answers. This confirms our embeddings capture real semantic differences, not noise.
Addressing Statistical Rigor
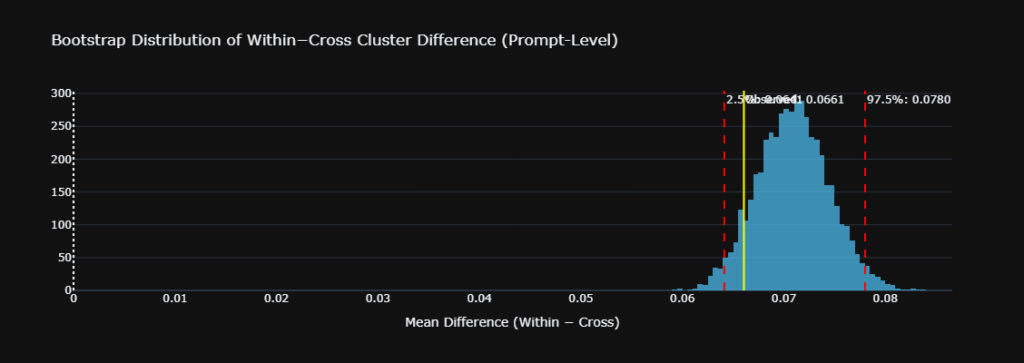
A naive t-test on 16,110 pairs would report t = 77.7, p approximately 0. But this is pseudoreplication. Each prompt participates in 179 pairs, violating the independence assumption.
We addressed this with a stratified prompt-level bootstrap. Two thousand iterations. Resampling prompts within each cluster to maintain balance and respect the dependence structure:
- Observed difference, within minus cross: plus 0.066
- 95% Bootstrap CI: [0.064, 0.078]
- Interpretation: The CI does not include 0. The effect is robust to prompt-level dependence.
Case Study 2: Fan-Out Query Similarity
Do similar prompts trigger similar grounding searches?
Yes. Also with strong evidence.
The 180 prompts triggered 1,620 unique grounding searches. Approximately 9 per prompt. The correlation between prompt similarity and query-set similarity was r = 0.869.
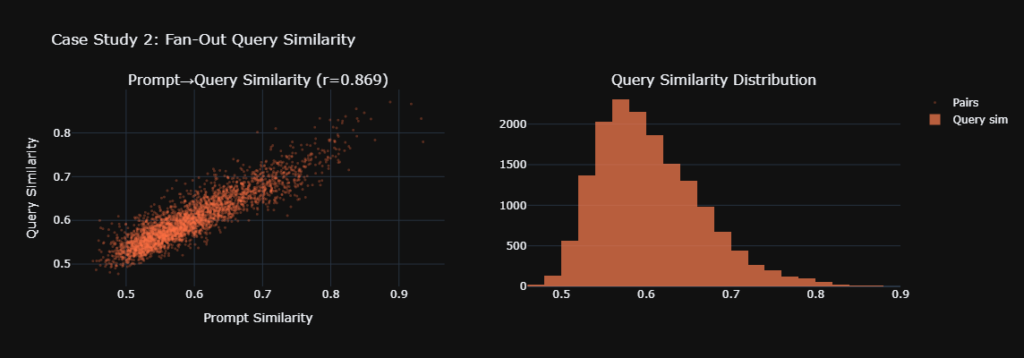
We used a symmetric best-match average to handle variable fan-out sizes. Some prompts triggered 5 searches, others 15. This prevents larger query sets from mechanically appearing more similar due to size alone.
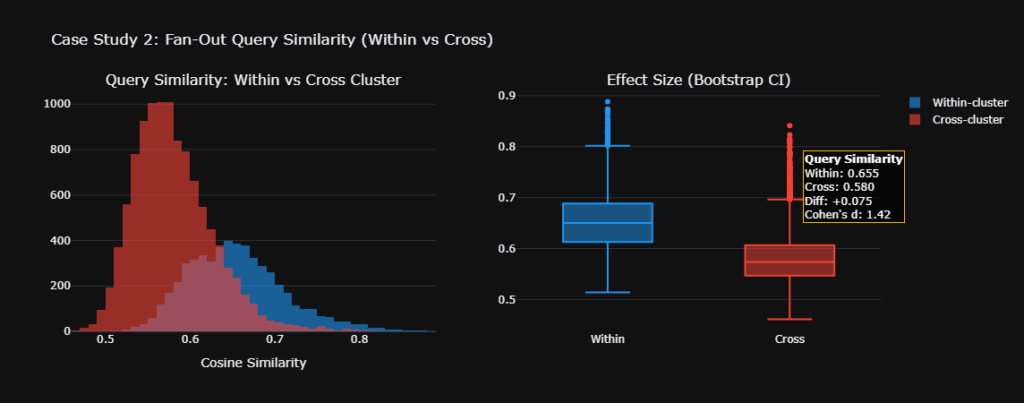
Statistical significance was confirmed via a Mantel permutation test. Two thousand permutations. This accounts for the matrix dependence structure. The empirical p-value was less than 0.001. Zero out of 2,000 random permutations matched or exceeded the observed correlation.
Grounding Source Analysis
We examined the titles of grounding sources across clusters:
- Over 80% of source titles were unique to a single topic cluster
- Cash flow prompts cited cash flow-specific resources. Fraud prompts cited fraud-specific resources
- Only generic finance portals like Investopedia appeared across multiple clusters
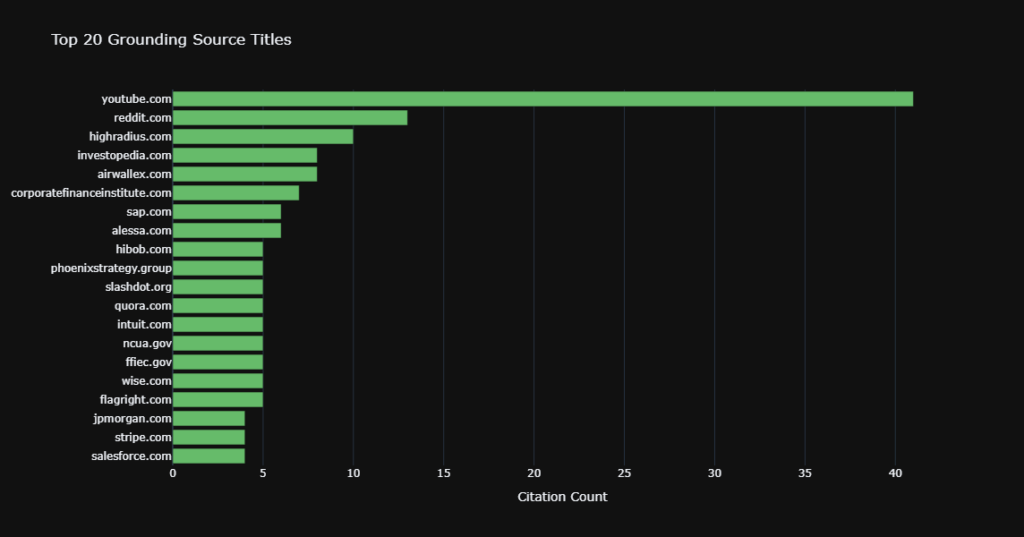
This high specificity means the AI is not lazily citing the same sources for everything. It’s performing targeted, topic-aware retrieval.
What This Means for AEO Strategy
1. Prompt Consolidation: Track Seeds, Not Everything
The core finding, r = 0.878, means you can group prompts by semantic similarity and track only one seed prompt per group.
Before consolidation: Track 500 prompts. 500 API calls per day. High cost.
After consolidation: Cluster prompts using cosine similarity greater than 0.75 threshold. Track approximately 50 to 75 seed prompts. 85% cost reduction.
The seed prompt’s response can be confidently extrapolated to the entire cluster.
2. Brand Mention Extrapolation
If your brand appears or doesn’t appear in the response to a seed prompt, you can infer the same for all prompts in that cluster. Response similarity of 0.70 within a cluster means the structure, content, and likely brand ordering are preserved across variations.
3. Fan-Out Query Coverage
Instead of optimizing content for every possible grounding query, focus on the top 10 to 15 grounding queries per topic cluster. Since similar prompts trigger overlapping searches, addressing one prompt’s grounding queries provides coverage for the entire cluster.
The math: 180 prompts generated 1,620 queries. But within a cluster, the top 15 queries cover the vast majority of search behavior. Optimizing for 45 queries, 15 times 3 clusters, is far more efficient than optimizing for 1,620.
4. Content Architecture
The source title specificity, over 80% unique per cluster, tells you that generic catch-all content pages won’t work for AEO. The AI prefers topic-specific, authoritative content.
Don’t: Write one giant “Complete Guide to B2B Finance”
Do: Write dedicated pillar pages. “Cash Flow Forecasting for B2B SaaS”. “Cross-Border Payment Automation Guide”. “AML Compliance Checklist for Fintech”. Each pillar page should target the top grounding queries for its cluster.
Limitations and Future Work
What we didn’t test:
- Brand mention rank correlation. We measured overall response similarity but didn’t extract and compare the specific order in which brands are mentioned. A follow-up using Kendall’s tau on brand rankings would strengthen the consolidation argument.
- Temporal stability. Our data represents a single point in time. Running the same seeds weekly for 4 to 8 weeks would confirm whether the r = 0.878 relationship holds as the AI model updates.
- Cross-model consistency. This study used Google Gemini. Testing with ChatGPT with Bing grounding, Perplexity, and Claude would determine whether consolidation strategies transfer across AI platforms.
- Domain breadth. All prompts were in B2B finance. The consolidation ratio may differ for other verticals like healthcare, legal, or e-commerce.
Methodological Notes
- All statistical significance tests used dependence-aware methods. Prompt-level bootstrap and Mantel permutation test rather than naive pairwise tests.
- Similarity was measured via neural embeddings, Gemini Embedding-001, not bag-of-words approaches.
- Query-set similarity used symmetric best-match averaging to normalize for variable fan-out sizes.
Conclusion
This study provides strong, statistically robust evidence that similar prompts produce similar AI responses and trigger similar grounding searches. The practical implication is clear: AEO does not require tracking every conceivable prompt variation.
By clustering prompts semantically and monitoring representative seeds, companies can achieve comprehensive AEO coverage at a fraction of the cost. The data suggests an 85% reduction in monitoring workload is achievable without sacrificing insight quality.
For AEO practitioners, the message is simple: Work smarter, not harder. One prompt can represent many.
This research was conducted by Kojable as part of our ongoing work in Answer Engine Optimization. The full methodology, code, and data are available on request.
Tools used: Google Gemini 3.0 Flash with grounding, Gemini Embedding-001, Python with NumPy, SciPy, Plotly, and scikit-learn.
Leave a Reply