Quick Answer: Yes, but the impact is strategic rather than overwhelming. AI does personalize search results based on professional roles, but it’s just one piece of the puzzle.
- The Takeaway: Highly operational roles (like AR and AP managers) get highly tailored AI responses, whereas generalist roles (like finance analysts) receive much more generic outputs.
- The Data: In a blocked permutation test of 988 finance prompts, we found effect sizes ranging from Cohen’s d = 0.48 to 0.95.
- The Reality Check: While 72% of this personalization survives even when we strip out role-specific jargon, persona only accounts for about 5% of the total response variance. Intent, topic, and industry context are still the heaviest hitters.
What This Research Examined
We tested whether AI search engines genuinely adapt content to professional personas or simply echo job titles back. Specifically: when a CFO and an AR manager both search for cash flow guidance with the same underlying intent, does the AI produce substantively different answers?
Sample: 988 prompts across 12 B2B finance personas (~82 per role) Method: Blocked permutation tests with vocabulary ablation controls Significance: All findings p < 0.002 unless noted
Key Findings: AI Persona Personalization by the Numbers
| Finding | Metric | Interpretation |
|---|---|---|
| Persona-response correlation | r = 0.22 (r² = 0.048) | Small-to-medium effect; 5% variance explained |
| Within-persona similarity premium | +0.062 cosine similarity | Responses to same role cluster measurably |
| Effect after jargon removal | 72% of signal survives | Substantive adaptation, not vocabulary echoing |
| Strongest persona effect | Cohen’s d = 0.95 (AR manager) | Very large differentiation |
| Weakest persona effect | Cohen’s d = 0.48 (finance analyst) | Medium effect; overlaps with other roles |
Confidence intervals: ±0.16 for Cohen’s d estimates (95% level)
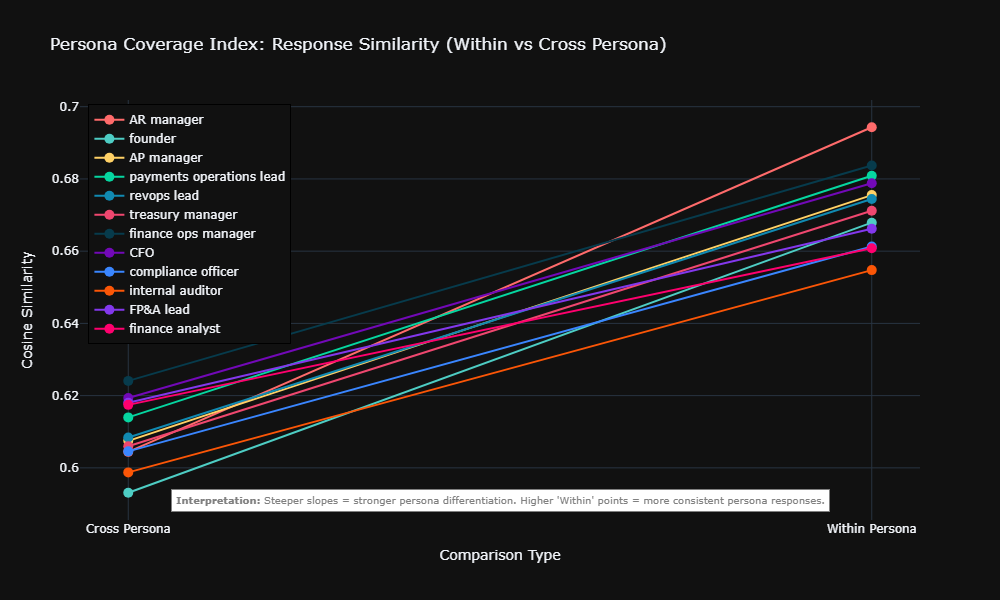
Does AI Actually Change Content or Just Word Choice?
Common misconception: AI personalization is cosmetic—swapping job titles while delivering identical advice.
Reality: Ablation testing proves substantive adaptation.
We mathematically stripped all role names, industry jargon (“collections velocity,” “covenant compliance”), and professional vocabulary from responses, then re-measured similarity. The persona signal dropped 28%—from +0.062 to +0.045—but remained statistically significant (p = 0.002).
What this means: The AI alters advice structure, prioritization, and strategic framing based on role context, not just surface language.
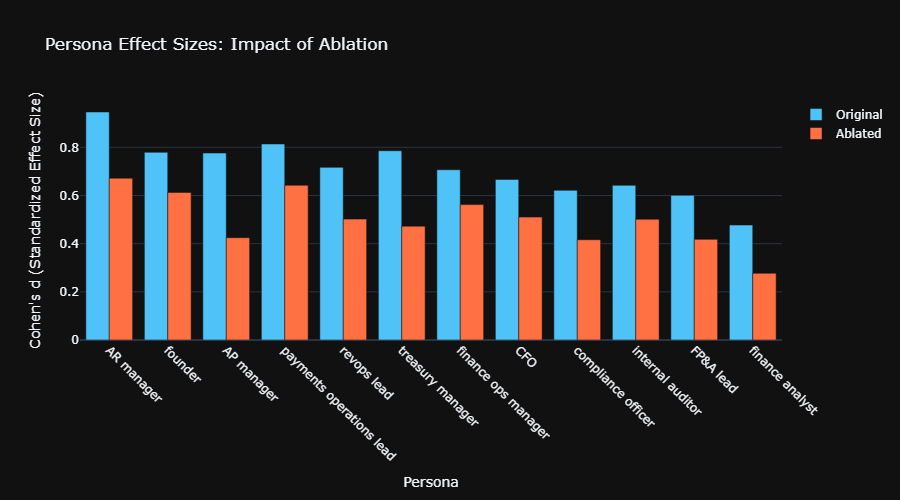
Which Finance Roles Trigger the Most Distinctive AI Responses?
Not all personas receive equal AI differentiation. Operational and risk-focused roles show strongest signal; generalist roles blur together.
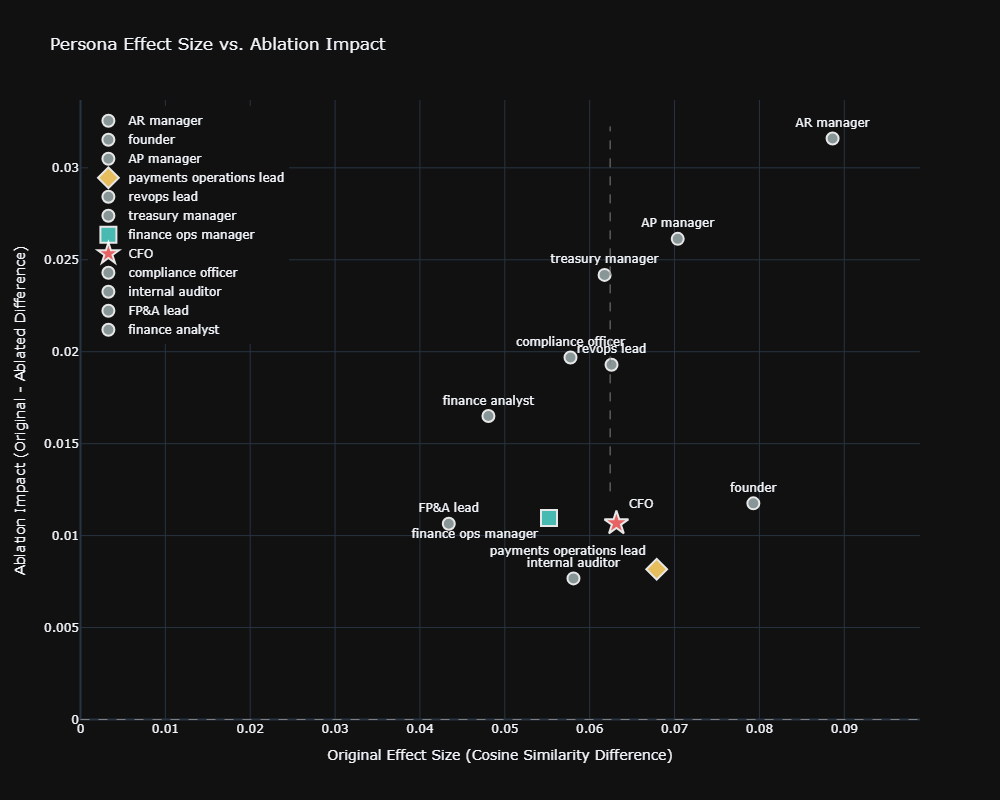
High-Differentiation Roles (Cohen’s d > 0.75)
| Role | Original d | Ablated d | Why Distinctive |
|---|---|---|---|
| AR manager | 0.95 [0.63, 1.27] | 0.68 | Specific operational metrics (DSO, collection targets) |
| Payments ops lead | 0.81 [0.50, 1.14] | 0.65 | Technical payment systems focus |
| Founder | 0.78 [0.46, 1.10] | 0.62 | Strategic/growth framing vs. operational |
| AP manager | 0.78 [0.46, 1.10] | 0.48 | Vendor management, cash timing priorities |
Moderate-Differentiation Roles (Cohen’s d 0.50–0.75)
- CFO, FP&A lead, compliance officer, internal auditor, finance ops manager, revops lead, and Treasury manager*.
Low-Differentiation Role (Cohen’s d < 0.50)
- Finance analyst: d = 0.48 [0.16, 0.80] original, 0.28 ablated
Strategic implication: If your ICP is a finance analyst, persona-based AEO optimization delivers weak returns. Invest in industry vertical and use-case differentiation instead.
*Note on Treasury Managers: While their final text responses show moderate differentiation, they actually trigger the highest distinctiveness of any role in backend search behavior (Query Fan-Out d = 0.95)**. The AI searches the web completely differently for them, even if the final text output is more constrained.
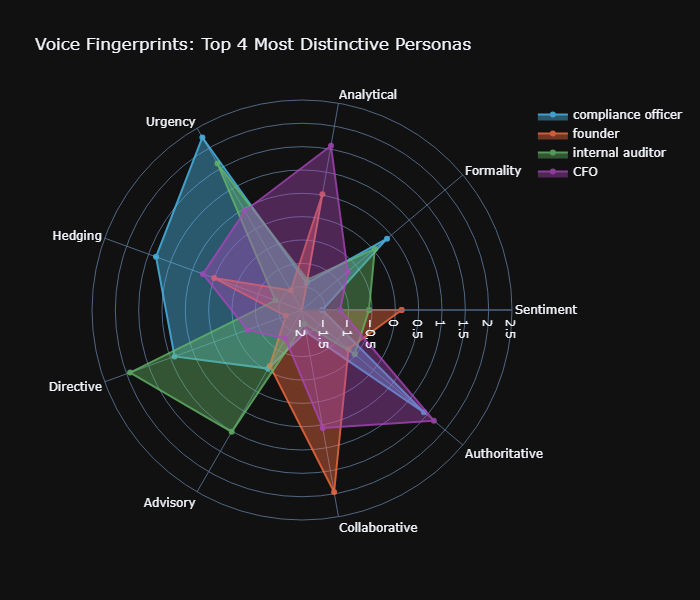
How Does AI Tone Change for Different Finance Roles?
Beyond content structure, AI adapts communication register measurably:
| Feature | Lowest | Highest | Pattern |
|---|---|---|---|
| Formality | Founder (13.8) | AP manager (16.1) | Operations roles get formal register |
| Analytical density | Compliance officer (4.0) | FP&A lead (7.0) | Planning roles get data-heavy content |
| Urgency framing | Founder (0.53) | Compliance officer (1.13) | Risk roles get alarm language |
| Sentiment | Compliance officer (0.23) | Finance analyst (0.67) | Risk-averse roles get negative tone |
| Directive voice | Founder (0.65) | Internal auditor (1.04) | Audit roles get imperative instructions |
Statistical basis: Kruskal-Wallis H-tests, p < 0.05 with Bonferroni correction; effect sizes small-to-medium (η² = 0.06–0.12)
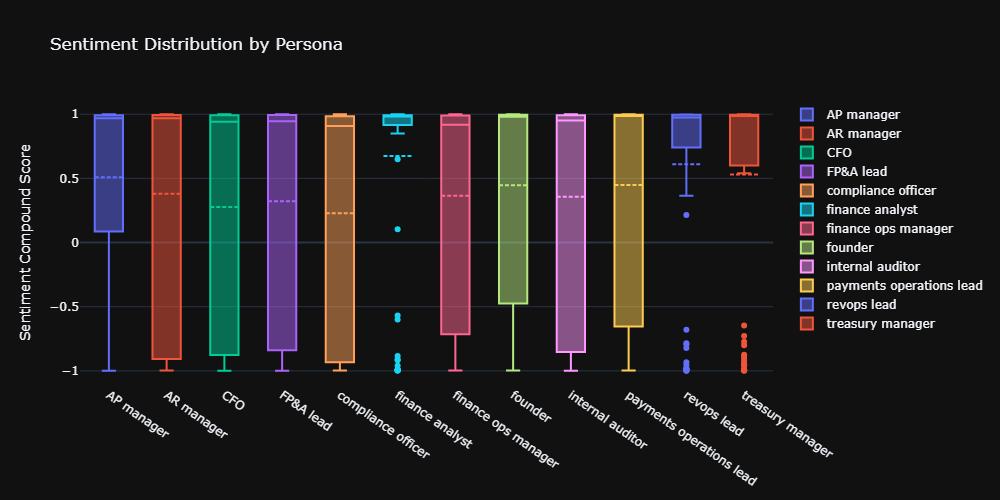
Do AI Search Queries Differ by Persona Too?
AI search engines don’t just generate different answers—they execute different background searches depending on who’s asking.
Query fan-out similarity results:
- Original queries: +0.054 within-persona gap (p = 0.002), r = 0.23
- Ablated queries: +0.036 gap survives (p = 0.002)
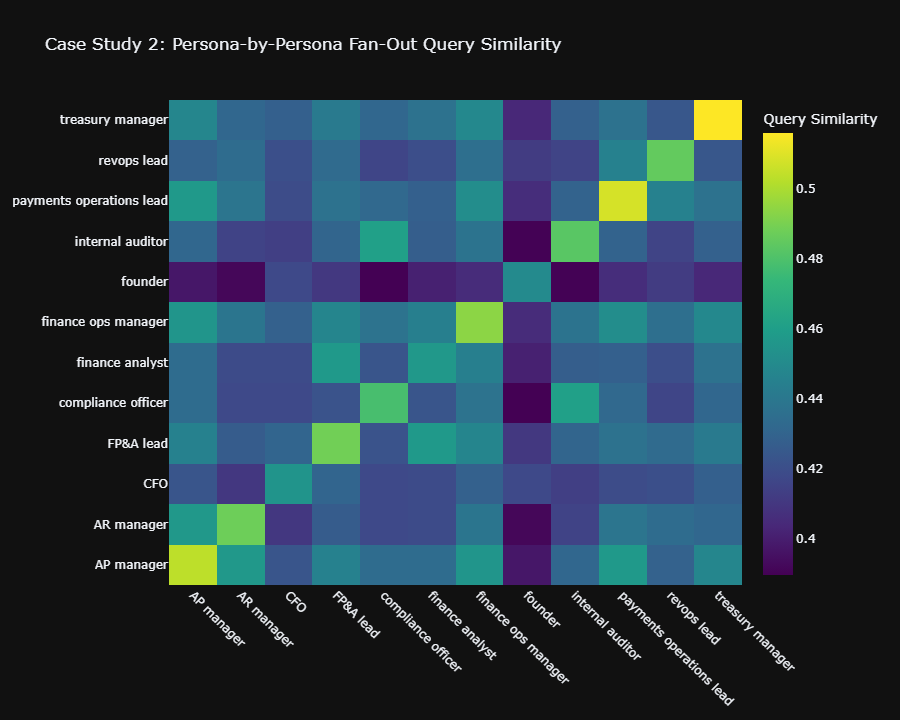
Translation: The AI reformulates search queries differently for different roles, retrieving distinct source material before generating responses. This suggests persona adaptation occurs at the retrieval layer, not just generation.
3 AEO Tactics Based on This Research
1. Prioritize Operational Roles for Persona Targeting
AR managers, AP managers, and payments ops leads trigger the strongest AI differentiation. Build dedicated content streams for these roles with specific operational metrics and workflow context.
2. Use Industry/Use-Case Differentiation for Generalists
Finance analysts show weak persona signal. Instead of role-based content, target this ICP through industry vertical expertise (SaaS financial operations, healthcare revenue cycle) and specific use cases (month-end close automation, board reporting).
3. Match Register to Role Expectations
AI adapts tone significantly by persona. Your content should mirror:
- Formal, analytical register for FP&A and treasury
- Urgent, risk-aware framing for compliance and audit
- Collaborative, strategic tone for founders and CFOs
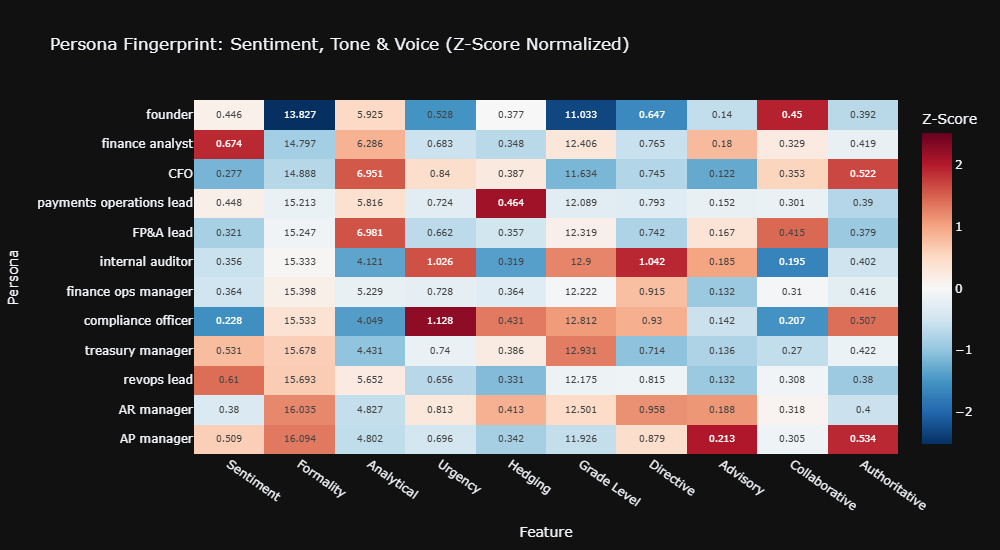
How to Optimize Content for AI Persona Targeting
Do:
- Include specific operational metrics relevant to the role (DSO for AR, days payable outstanding for AP)
- Structure content around role-specific priorities (runway protection for CFOs, retention balance for AR managers)
- Use industry-standard terminology naturally—AI recognizes professional vocabulary as context signals
Don’t:
- Over-optimize for generic “finance” personas—weak differentiation signal
- Rely solely on job title mentions—72% of effect is substantive
- Ignore confidence intervals—finance analyst targeting shows high uncertainty (d = 0.48 ± 0.32)
Methodology: How We Measured AI Persona Effects
| Component | Specification |
|---|---|
| Sample size | 988 responses |
| Personas | 12 B2B finance roles |
| Topic clusters | Cash flow, payment processing, fraud detection |
| Statistical test | Blocked permutation test (persona shuffled within topic×intent blocks) |
| Permutations | 500 overall, 200 per persona |
| Ablation method | Regex removal of role vocabulary, names, jargon; re-embedding |
| Similarity metric | Cosine similarity (OpenAI text-embedding-3-small) |
| Tone analysis | VADER (sentiment), Flesch-Kincaid (grade level), keyword density, imperative/modal ratios |
| Significance testing | Permutation p-values, Kruskal-Wallis H-tests with Bonferroni correction |
Limitations: Confidence intervals estimated via standard error approximation; individual persona samples (~82 responses) limit precision for smaller effects; query fan-out infers search behavior from query similarity rather than direct search log access.
Bottom Line for AEO Strategy
AI search engines do treat professional personas differently—but the effect is strategically meaningful, not dominant. Persona explains roughly 5% of response variance, with 72% of that signal coming from substantive content adaptation rather than vocabulary matching.
High-confidence targeting: Operational finance roles (AR, AP, payments, treasury) Low-confidence targeting: Generalist roles (finance analyst) Primary optimization priority: Topic relevance and intent alignment remain more important than persona tailoring
Research Context
Research by: Kojable
Tools: Google Gemini (grounding), OpenAI Embeddings, Python (NumPy, SciPy, Plotly, VADER)
Key Terms: Understanding the Data
To fully grasp how AI adapts to different personas, it helps to understand the statistical methods used to measure it. Here is how we define our core metrics:
- Ablation (in AI Prompt Testing): In natural language processing, ablation is the process of intentionally removing specific variables to see how the system’s output changes. In this study, ablation meant mathematically stripping all role names, job titles, and industry jargon (e.g., “collections velocity”) from the AI’s responses. This allowed us to measure if the AI was actually changing its underlying advice, or just echoing back vocabulary.
- Cohen’s d (Effect Size): Cohen’s d is a statistical metric used to measure the standardized size of a difference between two groups. In the context of Answer Engine Optimization, it tells us how intensely the AI differentiates its answers for a specific role. A score below $0.5$ is a weak/medium effect, while a score above $0.8$ (like the AR Manager’s $d = 0.95$) represents a massive, highly distinct variation in how the AI treats that persona.
- Blocked Permutation Test: A rigorous statistical test used to prevent false positives. Instead of just scrambling all the data randomly, we shuffled the persona labels only within their specific topic and intent categories. This ensures that any differences we found were strictly driven by the persona, not because the AI was answering a completely different type of question.
- Cosine Similarity: A metric used to measure how semantically similar two pieces of text are, regardless of their length. We used OpenAI embeddings to calculate the cosine similarity of the AI’s responses, proving mathematically that responses generated for the exact same persona cluster closer together than responses for different personas.
Related Questions
How much of AI personalization is real versus vocabulary echoing? 72% of persona signal survives complete vocabulary ablation, proving the AI adapts substantive advice structure, not just word choice.
Which B2B roles trigger the most distinctive AI search results? Operational specialists (AR managers, payments ops leads) show very large effect sizes (d > 0.8). Strategic roles (CFOs, founders) show medium-large effects. Generalists (finance analysts) show weak, uncertain differentiation.
Is persona-based content optimization worth the investment? Yes for operational roles with specific workflows and metrics; no for generalist roles where industry and use-case targeting outperforms persona targeting.
Leave a Reply