Does AI use different citation sources for different personas?
Yes. True persona-specific AI grounding means that while the total number of citations an AI generates is dictated entirely by prompt complexity, the specific domains it cites change significantly based on the assigned professional role.
What is the Core Hypothesis Behind Persona-Specific AI Grounding?
If an AI is truly persona-aware, it must change its underlying evidence base, not just its tone.
Our hypothesis was simple: an AI prompted to act as a CFO should not pull data from the same websites as an AI prompted to act as an Accounts Payable Manager.
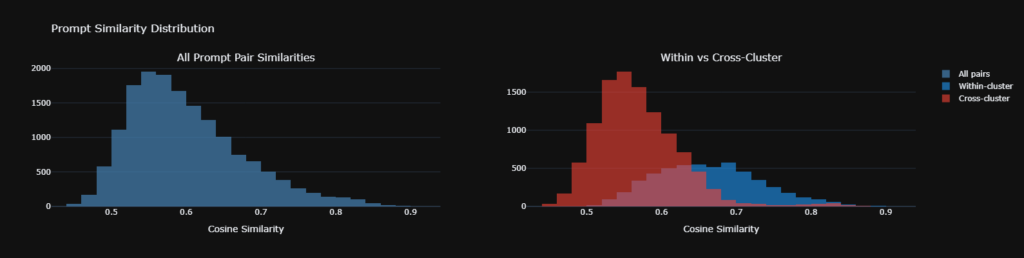
True persona adoption requires structural shifts in citation volume and source composition.
A mere change in vocabulary is just superficial styling; a change in the retrieval supply chain is a fundamental behavioral shift.
Why is Persona-Specific Grounding Important?
Understanding how persona-specific AI grounding alters its retrieval process based on persona fundamentally impacts how we build, optimize, and evaluate AI systems.
- Product Teams: You can steer retrieval pipelines based on user profiles to radically improve UX.
- Marketing Teams & SEOs: Tracking prompt intents is no longer enough; you must track who the prompt is designed for to optimize for AI visibility.
- Evaluation Teams: QAing language model outputs requires testing the actual composition of evidence, verifying that the AI isn’t citing generic wikis for expert-level queries.
- Governance: You must detect and mitigate retrieval bias to ensure that specific roles aren’t systematically fed lower-quality data.
How Did We Test This? (Our Process)
We built an end-to-end extraction and normalization workflow to rigorously test grounding behavior across 988 responses covering 12 distinct finance personas.
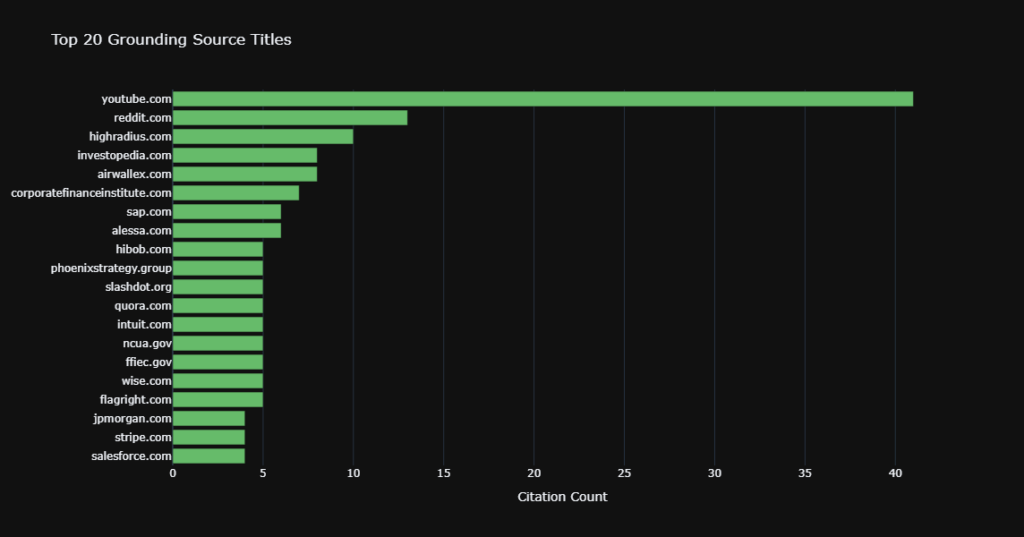
First, we extracted the persona-specific AI grounding sources. Because the raw URI fields often contained generic Vertex AI redirect loops, we parsed the actual title fields and normalized them into clean root domains using tldextract.
We then deduplicated these domains strictly within each response to prevent double-counting. Finally, we computed advanced informational metrics, transforming raw citation frequencies into Shannon entropy and Pielou’s Evenness (J) to measure true source diversity.
Why Did We Use Advanced Statistical Models?
We avoided naive t-tests because they consistently generate false positives by failing to account for shared topic structures and structural confounders.
When analyzing highly skewed, sparse count data across thousands of dimensions, basic statistics inflate significance. Because certain topics (like “fraud detection”) inherently require more citations than others, we needed models that could isolate the persona’s true marginal effect.
- Negative Binomial GLM: We used this to properly analyze citation count data, controlling for query intent and cluster complexity to prove that volume differences were driven by the query, not the persona.
- PERMANOVA (Bray-Curtis): We deployed this to test for actual, multi-dimensional composition differences across a massive 1,308-domain distance matrix without arbitrary cutoffs.
- PERMDISP: We used this to verify that the domain shifts identified by PERMANOVA were driven by genuine persona-driven curation, rather than just statistical noise or varying dispersion spreads between groups.
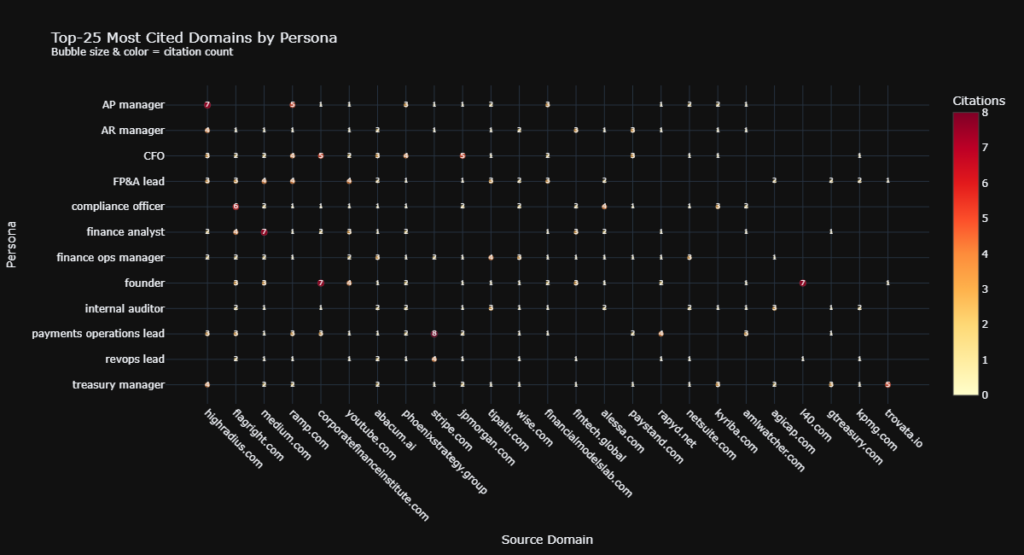
Key Findings: How Persona-specific AI Grounding Adapts Its Evidence Base
Our statistical suite revealed that the AI acts as a highly sophisticated routing mechanism, carefully matching domain supply to persona demand.
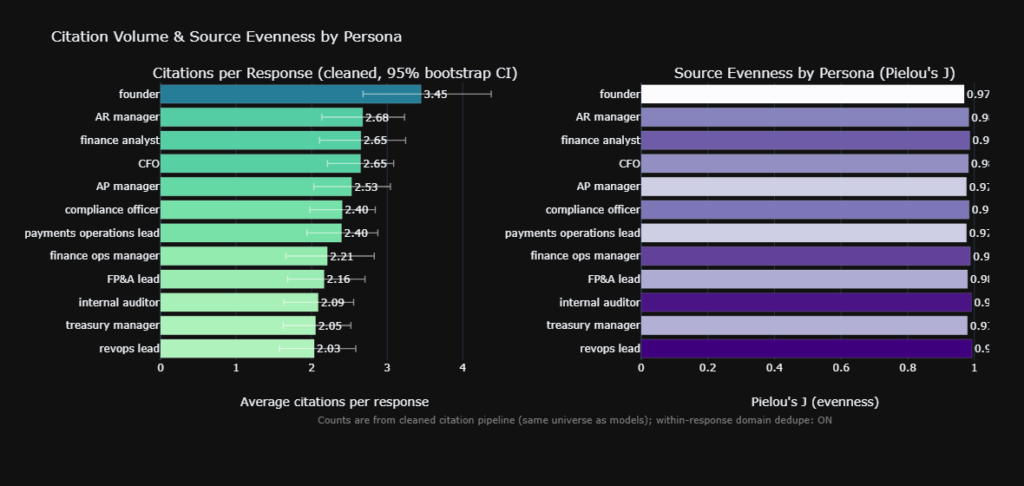
- Volume is Driven by Intent, Not Persona: The Kruskal-Wallis test initially suggested citation volume varied by persona. However, our Negative Binomial GLM ($p = 0.23$) proved this was a spurious correlation. The complexity of the query dictates the amount of evidence, not the persona.
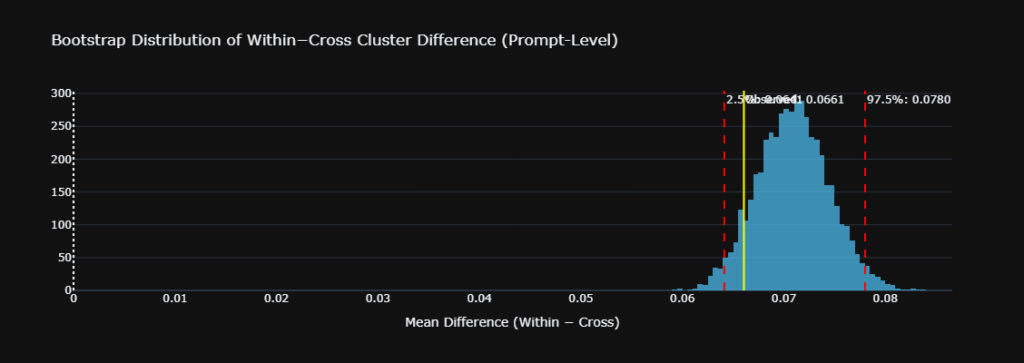
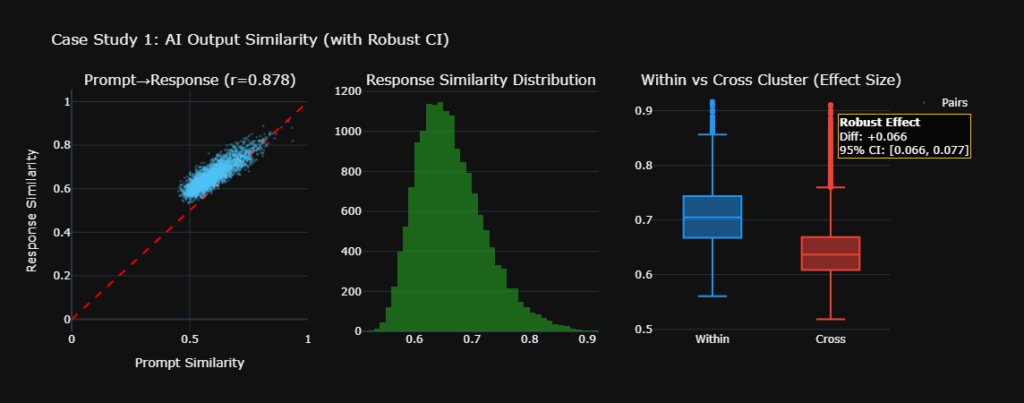
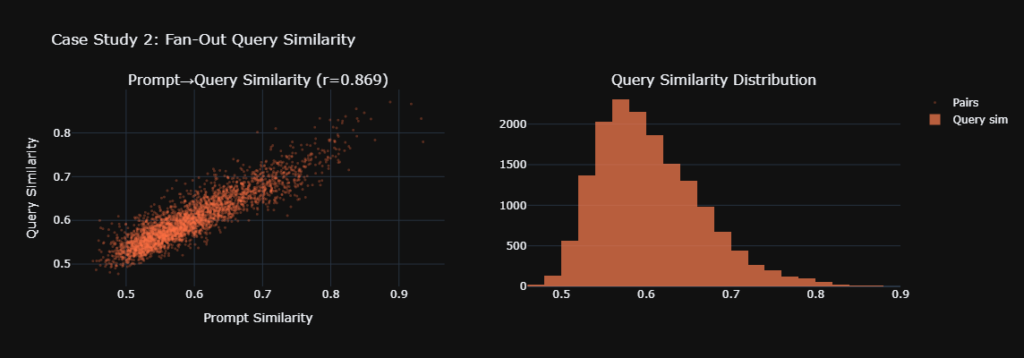
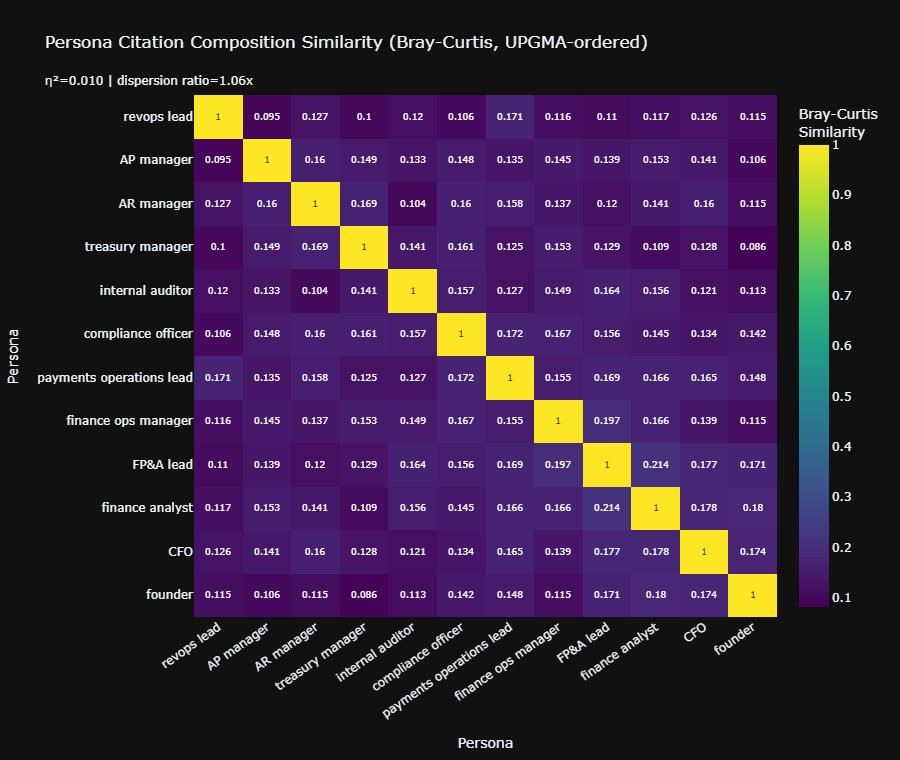
- Source Composition is Highly Persona-Dependent: Our PERMANOVA ($F = 1.31$, $p = 0.01$) definitively proved that the specific domains cited change based on the persona. The AI intelligently curates distinct informational diets for different roles.
- Cross-Persona Overlap is Shockingly Low: The Bray-Curtis similarity matrix revealed a mean off-diagonal overlap of just 14%. An AI acting as a Treasury Manager relies on a fundamentally distinct network of domains compared to an Internal Auditor.
- Source Diversity is Near-Perfect: Pielou’s Evenness scores consistently ranged between 0.96 and 0.99. The persona-specific AI grounding aggressively resists source monopolization, ensuring that no single persona becomes overly reliant on a single dominant domain.
- Algorithmic Clustering Validates Logic: When we mapped persona source similarities via hierarchical clustering, related roles like AP Manager and AR Manager organically grouped together. The math alone correctly mapped the latent business relationships.
Key Terms (Glossary)
- Ablation: Processing data by systematically removing components (e.g., stripping the persona from a prompt) to isolate and measure the original component’s true effect.
- Negative Binomial GLM: A generalized linear model specifically designed to handle overdispersed count data (like citation volume), controlling for confounding variables to prevent false positives.
- PERMANOVA: Permutational Multivariate Analysis of Variance; a non-parametric test used to assess whether different groups have significantly different compositions across a complex, high-dimensional space.
- Bray-Curtis Similarity: A statistic used to quantify the compositional similarity between two different sites (or in our case, personas) based on counts across intersecting data points.
- Pielou’s J (Evenness): A metric derived from Shannon entropy that measures how evenly distributed frequencies are, normalizing for sample size to allow fair comparisons between datasets of different sizes.
Frequently Asked Questions (FAQ)
Does prompting an AI with a specific persona make its answers longer?
Not inherently. Our data shows that while certain personas appear to generate more citations or text, this is actually driven by the complexity of the underlying query topic, not the persona itself.
How do we know the AI isn’t just pulling from the exact same sources every time?
Our analysis using Pielou’s Evenness metrics proves the AI relies on a highly fragmented, ultra-diverse data supply. Across all personas, the AI effectively avoids monopolization by pulling from over 1,300 distinct root domains.
Will optimizing for one persona hurt my visibility for another?
Yes, it is highly likely. Because the AI demonstrates only ~14% source overlap across different B2B roles, ranking for an “FP&A Lead” prompt means you are competing in a largely distinct domain pool than an “AR Manager” prompt.