TL;DR: The Business Bottom Line
Mastering AEO in SEO requires isolating the exact mathematical relationship between your native search rank and how generative engines extract your brand data.
- The Core Reality: Ranking first on traditional search engine results pages guarantees the artificial intelligence models will ingest your factual data, but it mathematically fails to guarantee an explicit product recommendation.
- The Revenue/Visibility Impact: Securing the top search position increases factual entity visibility by 4.3 percent over lower results, yet the explicit endorsement rate remains entirely flat across the top five search positions.
- The Strategic Pivot: Marketing leaders must split their search strategy into distinct factual indexing and product endorsement tracks, shifting resources to secure placements within highly ranked software blogs over lower ranking legacy institutional sites.
Note: The remainder of this report details the exact statistical methodology, causal inference models, and raw data used to reach these conclusions. It is written for data scientists, machine learning engineers, and technical search professionals.
The Core Problem & Hypotheses
As Generative AI systems mediate information retrieval, search visibility metrics require strict empirical reevaluation. We tested whether a high native search rank compels a Large Language Model to extract entities or recommend products at a higher frequency.
We pre-registered and tested two formal hypotheses within a Google Vertex AI Search configuration:
H2A (Factual Extraction): Generative AI architectures enforce a positional bias during extraction, such that $P(\text{extracted} \mid \text{Rank 1}) > P(\text{extracted} \mid \text{Rank } k)$, where $k$ represents lower ranked evidence.
H2B (Recommendation Propensity): Entities sourced from Rank 1 hold a statistically higher probability of explicit recommendation, such that $P(\text{recommended} \mid \text{Rank 1}) > P(\text{recommended} \mid \text{Rank 3 to 5})$, controlling for source text brand density.
Experimental Setup & Methodology
Data aggregation relied on grounded conversational outputs across thousands of financial logic queries. To ensure tracking accuracy, we enforced a strict Closed-World Assumption. The pipeline mapped evidence URLs to canonical domains and tracked only the entities strictly traceable to the provided grounding sources.
We evaluated entity extraction using a robust four layer funnel to prevent false negatives:
- Regex Matching: Exact string matching of brand names in the generated response.
- spaCy NER: Implementation of the
en_core_web_smmodel with a customEntityRulerinjected with a specialized brand dictionary to captureORGandPRODUCTclassifications. - Dictionary Lookup: Mapping localized product strings back to their parent canonical domains.
- LLM Implicit Extraction: A fallback evaluation using
gemini-3.1-pro-previewto identify implicit non-named entity references based strictly on context.
To prevent confounding variables where top pages simply repeat their brand names to manipulate extraction, we engineered a Position-Weighted Brand Density control.
Mentions of an entity in the first 20% of the text received a 2.0x weight, and mentions in the top 50% received a 1.5x weight.
Isolating the Variables: Our Statistical Approach
We applied causal inference models to isolate the genuine effect of ranking position over simple correlation.
We corrected all final outputs for multiple hypothesis testing using the Benjamini-Hochberg procedure.
| Statistical Test | Variable Isolated | Rationale for Selection |
| Logistic Regression | Position-Weighted Brand Density | Residualizes hit rates by modeling $P(\text{mentioned} \mid \text{rank, brand\_density, cluster, intent})$. |
| Cluster-Aware Block Permutation | Query-Level Variance | Shuffles rank labels strictly within identical query clusters to account for localized intent variance. |
| Propensity Score Matching (PSM) & IPW | Causal Effect of Position | Isolates the causal effect of search ranking position from confounding text variables. |
Key Empirical Findings for AEO in SEO
Finding 1: The Positional Bias in Factual Extraction (H2A)
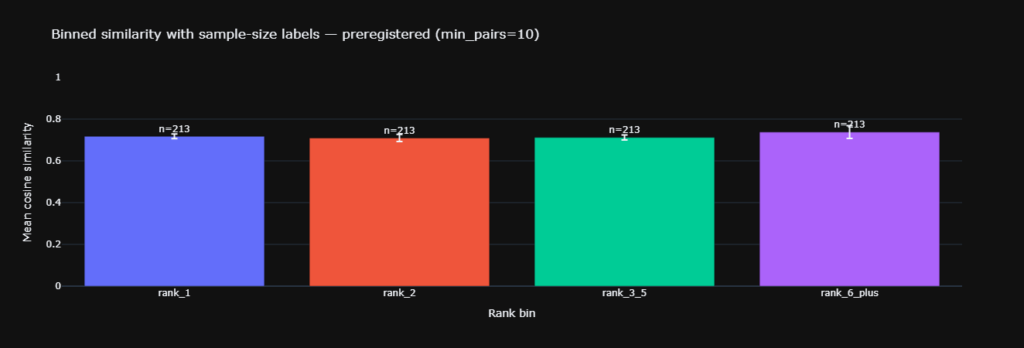
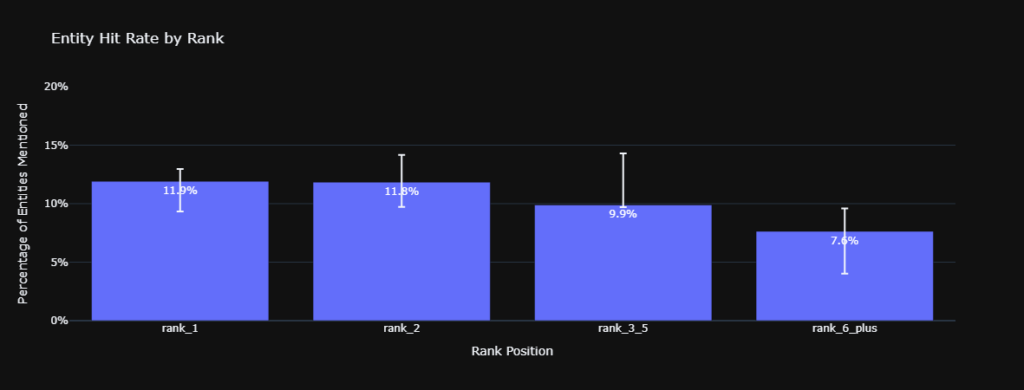
Analysis of the raw and controlled entity hit rates confirms a severe rank gradient for factual ingestion. The raw hit rate for Rank 1 sources sits at 11.9% ($n = 1645$).
This decays sequentially.
Rank 2 sits at 11.8% ($n = 1233$), Rank 3 through 5 falls to 9.9% ($n = 1840$), and Rank 6 and above drops to 7.6% ($n = 720$).
Applying the logistic control yields a 12.5% controlled hit rate for Rank 1 versus 8.5% for Rank 6 and above.
The 95% Confidence Intervals for Rank 1 [9.3%, 12.9%] and Rank 6 and above [4.0%, 9.6%] do not overlap.
This demonstrates robust statistical significance and supports H2A.
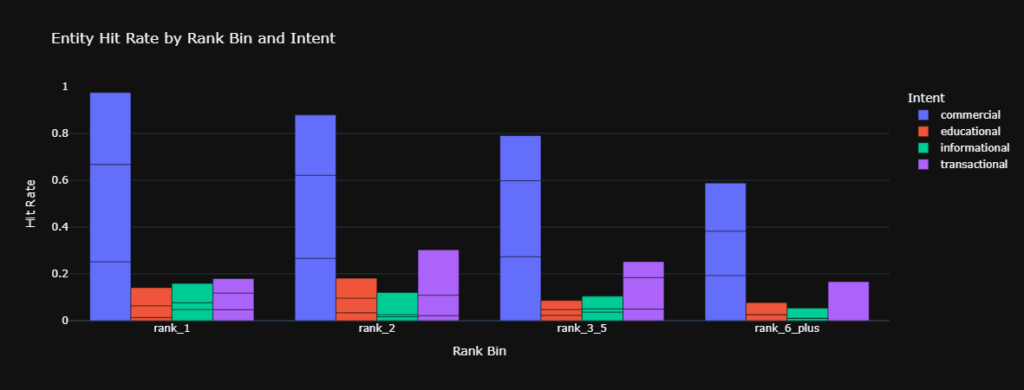
Finding 2: Intent Context Alters Positional Bias for AEO in SEO
Stratification of the dataset reveals that user intent contextually overrides positional bias. Within the commercial cash_flow cluster, Rank 1 achieved a 25.2% hit rate.
However, Rank 2 achieved 26.6%, and Ranks 3 through 5 secured 27.3%. In high-value commercial evaluations, the LLM actively diversifies its sourcing across the primary search window, displaying contextual rank agnosticism.

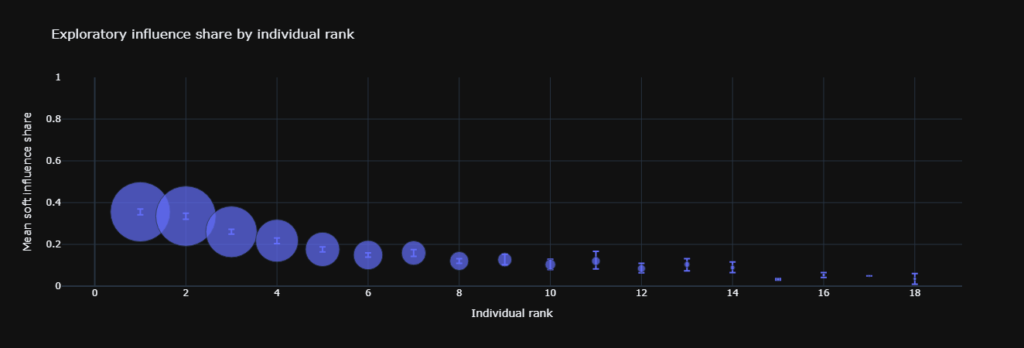
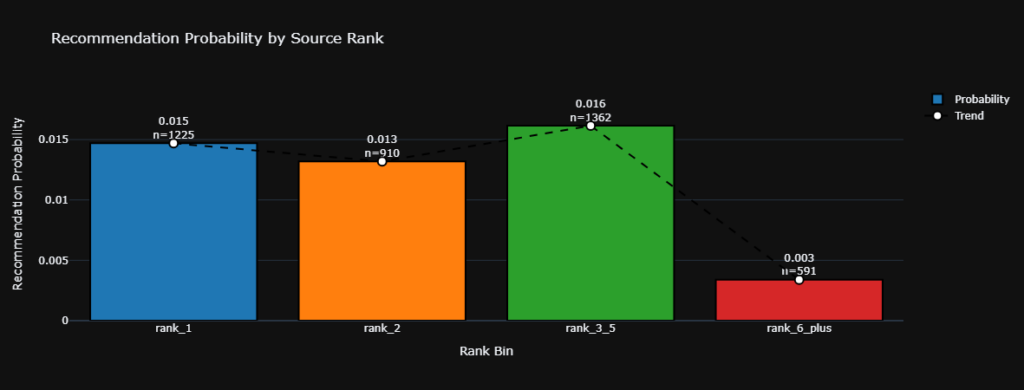
Finding 3: The Decoupling of Recommendation Propensity (H2B)
We utilized a zero-temperature LLM prompt requiring JSON output to map recommended entities to exact sections and text quotes.
This tested whether factual extraction translates into explicit recommendation propensity for AEO in SEO.
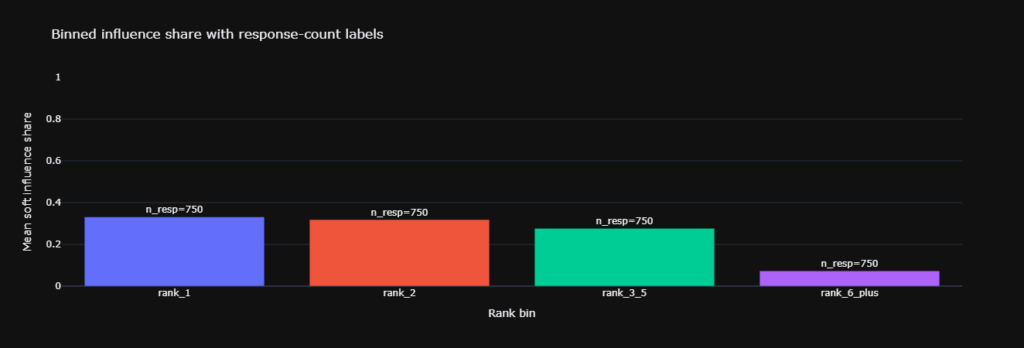
The probability metric $P(\text{recommended} \mid \text{rank})$ is non-monotonic and structurally low:
- Rank 1: 0.015 ($n = 1225$)
- Rank 2: 0.013 ($n = 910$)
- Rank 3 through 5: 0.016 ($n = 1362$)
- Rank 6 and above: 0.003 ($n = 591$)
A two-tailed T-test comparing Rank 1 and the Rank 3 through 5 cluster yielded a p-value of 0.571. This establishes no statistical difference. Search position does not reliably scale recommendation likelihood, meaning H2B is not supported.
Structural Impact
The data exposes an Authority Erosion Effect native to LLM grounding mechanisms. The mean textual brand density measured 3.96 for Rank 1 sources, while Rank 6 and above sources exhibited the highest density at 4.31.
A qualitative domain audit revealed Rank 1 is heavily populated by agile B2B software domains, whereas Rank 6 and above contains macro-financial institutions.
Because the generative model enforces positional bias, it systematically ingests narratives from Rank 1 domains.
This effectively circumvents the traditional extrinsic domain authority of the legacy institutions natively populating the lower ranks.
Technical Glossary (Entity Mapping)
- Closed-World Assumption: A strict data boundary premise where entity tracking is limited exclusively to the specific entities present within the provided grounding URLs.
- Position-Weighted Brand Density: A statistical control metric that assigns mathematical weight multipliers to brand mentions based on their proximity to the beginning of a document.
- Propensity Score Matching (PSM): A matching technique used to estimate the causal effect of a treatment by accounting for covariates that predict receiving the treatment.
- Cluster-Aware Block Permutation: A variance control method that shuffles rank labels strictly within identical query clusters to isolate local intent effects.
- Benjamini-Hochberg Procedure: A statistical method for controlling the false discovery rate during multiple hypothesis testing to ensure p-values reflect true significance.
- Zero-Temperature Prompt: A deterministic Large Language Model parameter setting that forces the model to select the most probable token, eliminating creative variance during extraction.
- Inverse Probability Weighting (IPW): A technique used to calculate statistics standardized to a pseudo-population to adjust for confounding variables in observational data.
Frequently Asked Questions
Q: How does search rank causally affect AEO in SEO?
A: Search rank dictates the probability of factual extraction by generative models, creating a measurable mathematical bias toward the first position over lower results.
Q: Does a top ranking statistically guarantee an AI brand recommendation?
A: No, empirical data shows recommendation probability remains flat across ranks one through five, confirming a p-value of 0.571 and no statistical advantage.
Q: What is the Authority Erosion Effect structurally?
A: It is a phenomenon where generative models prioritize factual extraction from highly optimized software domains ranking first, circumventing the native authority of lower ranking legacy institutions.
Q: Why did the study calculate position-weighted brand density?
A: This metric controls for confounding variables where top ranking pages might artificially inflate their extraction rates by repeating their brand name more frequently than lower pages.
Q: How do commercial intents alter baseline entity extraction rates?
A: High-value commercial queries cause the language model to diversify its context window, flattening the positional bias across the top five search results.
Q: What does a p-value of 0.571 prove regarding recommendation propensity?
A: It confirms that the minor variances in recommendation rates between the first position and positions three through five are strictly due to random chance, not rank position.
Conclusion
The empirical data confirms that generative retrieval architectures actively enforce a positional bias during factual extraction, granting a statistically significant advantage to Rank 1 sources. However, rigorous causal inference testing reveals this positional bias fails to cascade into recommendation propensity. Search rank serves strictly as a gatekeeper for factual entity ingestion, operating completely independently of the underlying mathematical logic the model utilizes for explicit brand endorsement.
Kojable
Kojable tracks how artificial intelligence models cite brands across different user personas and commercial intent clusters. If you are optimizing for AI search, we can show you exactly how your content performs in live retrieval.